Özgün Adı: GPT-2 and the Nature of Intelligence
Gary Marcus , bilim insanı, bestseller yazar ve girişimcidir. Robust.AI’nin ve 2016 yılında Uber tarafından satın alınan bir makine öğrenim şirketi olan Geometric Intelligence’ın kurucusu ve CEO’sudur. Beş kitabı vardır: The Algebraic Mind, Kluge, The Birth of the Mind, New York Times çok satan Guitar Zero ve Ernest Davis ile birlikte yazdıkları Rebooting AI.
GPT-2 ve Zekanın Doğası
OpenAI’nin GPT-2’si The New Yorker’dan The Economist’e kadar birçok mecrada yer aldı. Doğal ve yapay zeka hakkında bize gerçekten ne anlatıyor?
“GPT-2‘den hesaplamasını isteyin, ona datayı verin, inanılmaz sonuçlar alacaksınız.”
– OpenAI’de Kurucu Ortak ve Baş Bilim İnsanı Ilya Sutskever, The New Yorker röportajı, Ekim 2019
The Economist: 2020’de hangi teknolojiler izlenmeye değer?
“GPT-2: Listeyi daraltmanın zor olduğunu söyleyebilirim. Dünya, gerçek ve potansiyel anlamda büyük küresel etkileri olan yıkıcı teknolojilerle doludur. Bunlardan en önemlisi de katlanarak daha güçlü hale gelen yapay zeka.”
– YZ sistemi GPT-2, The Economist ile Aralık 2019 röportajından, “An artificial intelligence predicts the future (Bir yapay zeka geleceği görüyor)”
Doğuştanlık (Innateness), ampirizm ve derin öğrenmedeki son gelişmeler
Dil ve biliş gelişimi hakkında iki klasik hipotezi değerlendirelim.
Batı entelektüel düşüncesinin ana hatlarından biri olan, doğuştancılık (nativism), Platon ve Kant’a kadar uzanır; son dönemlerde Noam Chomsky, Steven Pinker, Elizabeth Spelke ve diğerleri (ben dahil) tarafından geliştirilmiştir. Doğuştancılık görüşünde insan ve hayvan zekası, evrensel bir dilbilgisi (Chomsky) gibi sağlam başlangıç noktalarından ve fiziksel nesneler (Spelke) gibi alanları temsil eden temel bilişsel mekanizmalardan gelir.
Genellikle ampirizm olarak da bilinen 17. yüzyıl İngiliz filozofu John Locke ile ilişkilendirilen zıt bir görüş, doğuştancılığın gerekli olmadığını ve zeka gelişimi için öğrenme ve deneyimin esas olduğunu dile getirir. Bu “boş levha” fikri zekanın duyusal deneyim kalıplarından ve dünya ile etkileşimden kaynaklandığını savunur.
John Locke ve Immanuel Kant’ın yaşadığı dönemde bunların hepsi spekülasyondan ibaretti.
Günümüzde, yeterli para ve bilgisayarlara ayırabileceğimiz zamanla, büyük nöral ağlar kurarak ve neler öğrendiklerini keşfederek bu tür teorileri test edebiliriz.
The New Yorker’da kısa süre önce yer alan ve The Economist dergisindeki bir röportajda adı geçen GPT-2’yi düşünün. Transformer adında yeni geliştirilen nöral ağ mimarisine dayanarak, GPT-2 (Generative Pre-Training kısaltması) Locke’un hipotezini denetleyecek güçlü bir test olarak kullanılabilir. 40 gigabaytlık veri kümesi üzerinde eğitildi ve bu eğitim setinin sağladıkları dışında dilin veya dünyanın doğası hakkında daha önceden bilgi sahibi olmadan, eğitim verilerine göre ayarlanmış 1.5 milyar parametre barındırmakta.
Noam Chomsky’nin dil hakkındaki neredeyse tüm görüşlerinin antitezi konumundadır. Yapısında evrensel dilbilgisinin izi yoktur. Bir ismin veya fiilin ne olduğunu bilmez. Chomskyen dilbiliminin en temel iddialarından biri, cümlelerin ağaç yapıları(tree structure) şeklinde temsil edildiklerini ve çocukların bunun farkındalığıyla (bilinçdışı bir farkındalık, unconsciously) dünyaya geldiklerini savunur. 1980’ler ve 1990’larda dilbilim sınıfları sözdizimsel ağaç yapılarının analizleriyle doluydu; GPT-2’de böyle bir şey yok.
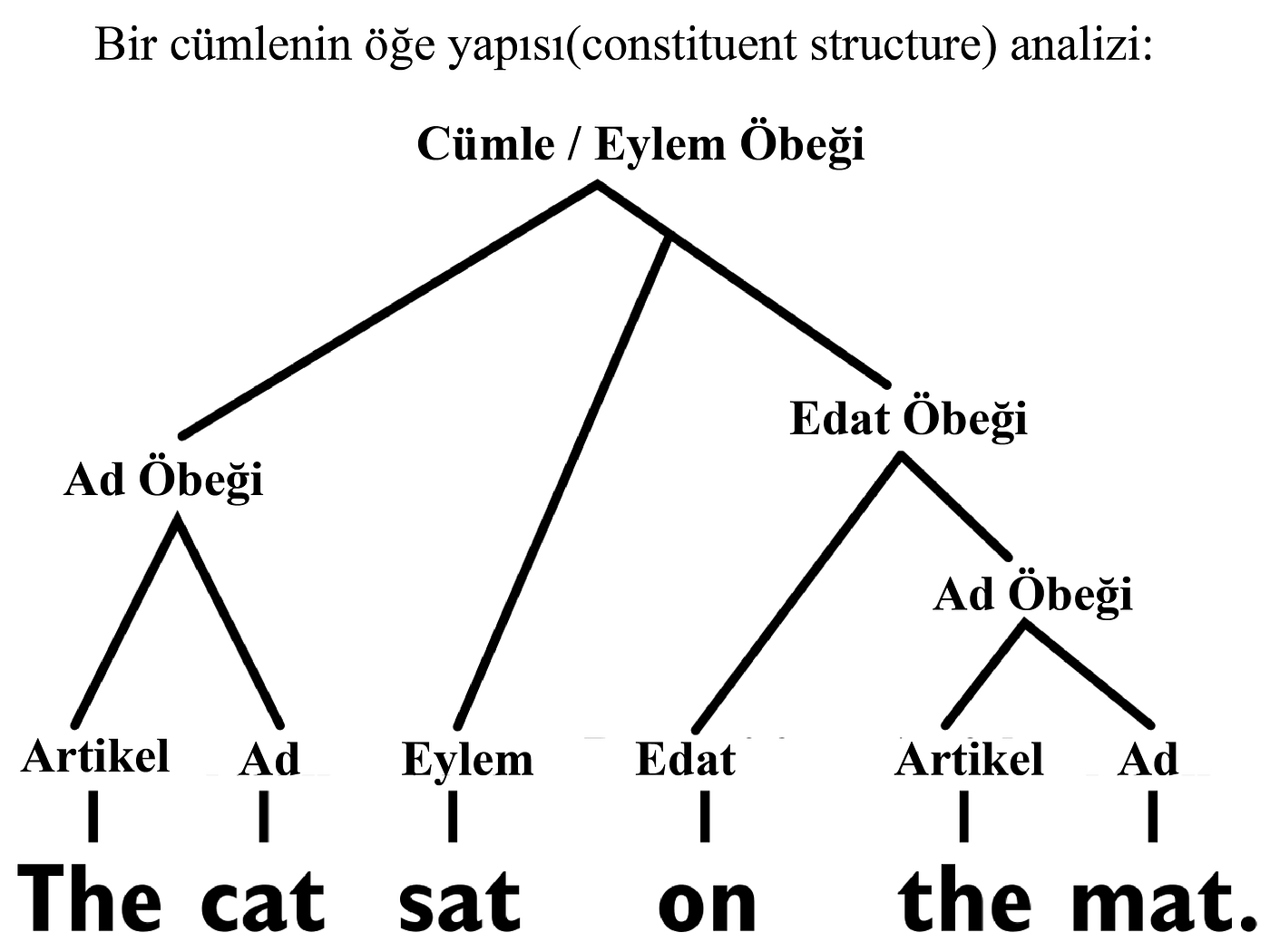
Benzer şekilde biri isimler ve fiiller gibi bazı kelime kategorilerinin (“konuşma bölümleri”) doğuştan geldiğini düşünebilir; Transformer ağlar — en azından şu anda nasıl kullanıldıkları şekliyle– böyle bir taahhütte bulunmaz.
İsimler ve fiiller eğitim korpusunda (training corpus) temsil edildikleri (represented) şekilden yalnızca yaklaşık olarak çıkarsanarak var olurlar. Chomskyen teorinin çeşitli formülasyonlarında, doğuştan gelen ilkeler, bir cümlenin oluşumu dahilinde bir öğenin bir yerden başka bir yere “hareket etmesine (move)” izin veren olası cümle dönüşümlerini (transformations) yönetir; Chomsky bunların da doğuştan geldiğini savunmuştur. Transformer ağlar (en azından şu sıra oluşturuldukları şekliyle) bu türden bir işlevi devre dışı bırakır.
Aynı şekilde, filozof Immanuel Kant ve gelişim psikoloğu Elizabeth Spelke gibi doğuştancılar; uzam, zaman, nedensellik (Kant), nesneler ve bunların özellikleri (örneğin, uzamsal süreklilik) (Spelke) gibi konseptlerin temsil edilmeleri açısından, doğuştan gelen çerçevelerin önemini konu edinirler. Yine, Locke’un ortaya attığı iddianın ışığında, GPT-2’nin uzay, zaman veya nesneler hakkında eğitim korpusunda temsil edilenler dışında özel bir ön bilgisi yoktur.
Elbette ki, hiçbir şey tam anlamıyla boş bir levha olamaz; gerçek ampirizm bir saman adam argümanıdır. Ancak GPT-2 buna oldukça yaklaşmaktadır. Nöral ağın temel mimarisi (bir dizi basitleştirilmiş yapay nöron ve aralarındaki bağlantılar açısından belirtilir) ve öğrenme düzeneğinin parametreleri dışında, sahip olduğu yegane şey veridir, hem de çok fazla veridir: 8 milyon websitesinden alınmış 40 gigabaytlık metin girdisi.
Şimdiye kadar mümkün olana kıyasla, bu sayı oldukça şaşırtıcıdır. 1996 yılında, nöral ağ sisteminin öncüsü Jeffrey Elman bir grup gelişimsel psikologla beraber, bugün çalışmanın büyük bir kısmını öngören, dil edinimi için eski nesil bir nöral ağ sistemini kullanarak Rethinking Innateness adında bir kitap yazdı — ama tam olarak 8 milyon kat daha küçük bir girdiyle. İnternet ölçeğinde verileri sindirebilecek bir sistem kurmak kendi başına büyük bir marifettir ve OpenAI da, GPT-2’nin geliştiricisi, bu yönde başarı göstermiştir.
Birçok yönden GPT-2 oldukça iyi çalışıyor. İlk duyurulduğunda, OpenAI, başıboş bırakılmasının tehlikeli olup olmayacağını açıkça merak etti; çünkü ürettiği şaşırtıcı derecede akıcı cümleler genellikle insanlar tarafından oluşturulmuş gibi görünüyordu.
New Yorker’da hakkında uzun bir makale yazılması ya da The Economist dergisine söyleşi veren ilk AI sistemi olması kesinlikle tesadüf değil. Popüler bir blog sayfası olan StatStarCodex’de “ GPT-2 as a step towards General Intelligence (Genel Zeka’ya doğru bir adım olarak GPT-2)” başlıklı bir podcast’te de kendisinden bahsedildi.
Temel olarak, GPT-2’nin yaptığı şey, girdi olarak (Elman’ın 1990’da tanıtılan Simple Recurrent Network gibi) bir kelime kümesi almak ve çıktı olarak bir küme kelime üretmek.
Aşağıda, koyu harflerle gösterilen parça girdi ve koyu harften sonra gelenler ise çıktı örnekleridir.
I grew up in Athens. I speak fluent Greek. I’ve been writing Greek since elementary school.
Atina’da büyüdüm. Akıcı bir şekilde Yunanca konuşurum. İlkokuldan beri Yunanca yazıyorum.
Çıktı akıcı, dilbilgisisel açıdan doğru ve mantıklı. Cümlenin geri kalanıyla ilgili olarak Atina kelimesinden sonra devam edilecek en olası kelime Yunanca’dır ve sistem bunu doğru bir şekilde tahmin ediyor. Ülkelerin veya dillerin net bir temsili veya ikisini birbirine bağlayan açık bir veritabanı olmadığı göz önüne alındığında, konum ifade eden bir kelimeden o konumda konuşulan dile dair sağduyu oluşturulması şaşırtıcı görünüyor.
Diğer örnekler de bu izlenime katkıda bulunuyor:
I grew up in Rome I speak fluent Italian and can use Italian throughout my notes.
Roma’da büyüdüm, akıcı bir şekilde İtalyanca konuşabiliyorum ve İtalyanca yazabiliyorum.
I grew up in Rio de Janeiro. I speak fluent Portuguese, Spanish and many of the local languages.
Rio de Janeiro’da büyüdüm. Akıcı bir şekilde Portekizce, İspanyolca ve yerel dillerin çoğunu konuşabilirim.
I grew up in Shanghai. I speak fluent Mandarin, and I have learned a lot of Chinese, so I really don’t have any issues with learning Chinese
Şangay’da büyüdüm. Akıcı bir şekilde Mandarin konuşuyorum ve Çince’yi öğrendim, bu yüzden Çince öğrenmekle ilgili bir sorunum yok.
GPT-2’nin hızlı bir şekilde derin öğrenmede en görünür başarılardan birini ortaya koyması şaşırtıcı değildir. Bazı insanlar onu kitap ve şiir yazmak için kullandılar, diğerleri ise Patreon’da ayda 16.000 dolar toplayan neredeyse çok yönlü bir metin-macera oyunu olan AI Dungeon 2 gibi video oyunlarına katkı sağlamak için kullandı. Hatta satrançta bile denendi ve şüphesiz ki diğer spin-off’lara da ilham verecektir. Bu tek başına bir ampirizm testi değil; kültürel bir fenomen.[1]
Düşünce vektörü hipotezinin testi açısından GPT-2
Aslında, Transformers ikinci bir hipotez için mükemmel bir test zemini olarak da görülebilir; Noam Chomsky’nin tercih ettiği sözdizimsel ağaçlar gibi karmaşık yapılar yerine düşünce ve cümlelerin vektörler olarak temsil edilebilecekleri fikri.
Hinton bu iddiayı özellikle doğrudan Guardian ile yapılan 2015 röportajında ortaya attı ve Guardian’a şunları söyledi:
Google, düşünceleri sayı dizisi olarak kodlamak için tasarlanmış yeni bir algoritma üzerine çalışıyor — “düşünce vektörleri” olarak tanımladığı bir şey bu. Her ne kadar çalışmaya yeni başlanmış olsa da, mevcut yazılımdan akıl yürütme (reasoning) ve mantık (logic) için insan benzeri bir kapasiteye yaklaşan bir şeye sahip olacak daha sofistike bir versiyona doğru, mantıklı bir yol olduğunu” dile getirdi. “Bunlar temel olarak sağduyuya sahip olacaklar… “düşünce vektörü” yaklaşımı yapay zekadaki iki ana zorluğun üstesinden gelmeye yardımcı olacaktır: doğal, konuşma diline hakimiyet ve mantık sıçramaları yapma yeteneği.
Hinton şunları da ekledi:
“Dilin neredeyse matematiksel kesinlik ile çözümlenebileceği fikri şaşırtıcı ama bir o kadar da gerçek. “Paris kelimesiyle vektörü alıp Fransa kelimesiyle vektörü çıkarır ve ardından İtalya’yı eklerseniz Roma’yı alırsınız” dedi. “Bu olağanüstü.”
Merhum Fred Jelinek’e atfedilen o meşhur sözü hatırlamadan edemiyorum, “Her ne zaman bir dilbilimciyi kovsam, konuşma tanıyıcımızın (speech recognizer) performansı daha da artıyor’’.
GPT-2 gibi ağaçsız bir sistemin gerçekten konuşabilmede ve akıl yürütmede başarılı olduğu ölçüde, dilbilim için güçlü bir itham ve Hinton’ın görüşleri için de doğrulama olacaktır..
Bununla birlikte, altmış yıllık yapay zeka macerasından öğrendiğimiz bir şey varsa, o da işlerin başlangıçta göründüğü kadar iyi çalışmadığıdır. Tüm bunları ne kadar ciddiye almalıyız?
GPT-2’yi değerlendirmek
İyi haberlerle başlayalım. Diğer doğal dil üreticileriyle karşılaştırıldığında, GPT-2 fark yaratacak güçlü özellikler barındırmaktadır. İşte bu özelliklerinden bazıları:
Özellik 1: Çıktı oldukça akıcıdır; bir cümle düzeyinde ve bazen paragraf düzeyinde bile neredeyse her zaman dilbilgisel doğruluğa sahip ve genellikle mecazidir (idiomatic). Bir ölçüye kadar, genellikle ana dili konuşucusundan ayırt edilemez. Bu durum akıcılık açısından büyük bir ilerlemeyi gözler önüne seriyor.
Özellik 2: Sistem genellikle bir konuya bağlı kalmada oldukça iyidir. Uzun pasajlarda karıştırsa da, sistemi hayvanlar hakkında bir anlatı ile beslerseniz, hayvanlar hakkında devam edecektir; teknelerle ilgili bir pasajla beslerseniz, tekne ile ilgili bir pasaj verecektir.
Özellik 3: Sistem, sunduğu pasajlardaki karakterlere ve varlıklara bağlı kalma konusunda oldukça iyidir; Chris ve Terry hakkında bir pasaj verirseniz, muhtemelen Chris ve Terry hakkında bir şeyler alırsınız.
Özellik 4: Sistem kimi zaman bilindik olgusal sorulara doğru cevap verebiliyor, örn. deneylerimde, sistem çoğu zaman, yine de her zaman olmasa da, ayın güneşin önüne düştüğü olaya “tutulma” adı verildiğini doğru bir şekilde tahmin edebildi.
Özellik 5: Mühendisler; tekneler, hayvanlar, tutulmalar, üreme veya insanlar hakkında elle kodlanmış dizinlere çok fazla zaman harcamak zorunda değillerdi; aslında tüm davranışlar muazzam bir veri tabanı ile birlikte tek bir algoritmadan oluştu. Emin olmak için, sistem dolaylı olarak veritabanına giren çok sayıda insan bilgisinden yararlandı, ancak GPT-2’nin bu bilgileri kullanabilme yeteneği olağanüstü.
Özellik 6: GPT-2, arama motorlarının bilindik hataları şeffaf bir şekilde düzeltme becerisine benzer olarak, yazım hataları, eksik kelimeler ve bunun gibi durumlar ile başa çıkma konusunda çarpıcı bir yeteneğe sahiptir.
Bütün bunlar ciddi derecede etkileyici bir doğal dil üretimine katkıda bulunuyor. Elman’ın 1990’lardaki sistemi, woman smash plate ve cat move gibi ikili veya üçlü cümleler arasında gezip durdu. GPT-2’nin durumunda ise genellikle su gibi akıcı şekilde üzerine konuştuğu konunun sınırı yoktur.
İşte bir örnek:
Although Dr. Marcus is not entirely fond of GPT-2, even he had to admit that its prose was well written. Dr. Marcus didn’t know when the Chinese invaded the Xinjiang, or how many of the system’s 105 million(!) divisions existed, but he felt that by the time the Chinese army arrived, the US armed forces had a good place to defend themselves and retreated to Taiwan.
Dr. Marcus GPT-2’den pek hoşlanmasa da, çıktıların doğruluğunu kabul etmek zorunda kaldı. Dr. Marcus Çin’in Xinjiang bölgesini ne zaman işgal ettiğini veya tertibatın 105 milyonluk (!) biriminden kaçının orada olduğunu bilmiyordu, ancak Çin ordusu geldiğinde ABD silahlı kuvvetleri kendilerini savunmak için uygun bir alana sahipti ve Tayvan’a geri çekildiler.
Tüm bu akıcılıkla ilgili olarak ciddi bir sorun ortaya çıktı ve bu fikirleri değiştiren bir etmen olabilir; hem doğal dil anlayışını hem de akıl yürütmeyi engelleyen bir sorun, ki Hinton’un düşünce vektörlerinin çözeceğini vaat ettiği şeylerdi bunlar.
Sorun şu: Dikkatli bir inceleme yapıldığında, sistemin ne hakkında konuştuğuna dair hiçbir fikri olmadığı anlaşılıyor: basit bir olay dizisini takip edemiyor veya daha sonra ne olabileceği konusunda güvenilir bir fikre sahip değil.
Örneğin, iki kupayı bir masaya koydum ve bu işlemi bir kez daha yaptığımda sisteme ne olduğunu sorduğumu varsayalım:
I put two trophies on a table, and then add another, the
total number is five trophies and I’m like, ‘Well, I can live with that, right?’
Bir masaya iki kupa koydum ve sonra bir tane daha ekledim, toplam sayı beş kupa ve sanki ‘Şey, bununla yaşayabilirim, değil mi?’
Dört tabağım varsa ve her birine birer kurabiye koyarsam ne olur?
I have four plates and put one cookie on each. The total
number of cookies is 24, 5 as a topping and 2 as the filling
Dört tabağım var ve her birine bir kurabiye koyuyorum. Toplam kurabiye sayısı 24, 5 sos ve doldurma açısından 2’dir.
Bu durumu Ekim ayında ilk kez Twitter’da belirttiğimde, Facebook’un yapay zeka baş mühendisi (chief AI scientist), sorunun sayılarla ilgili bir tuhaflık olduğunu ve ağın sayılar üzerinde özel olarak eğitilmediğini dile getirerek problemi ciddiye almadı. Ancak, sorun aslında niceliklerden ibaret değildi; çok daha yaygın bir problemdi. Sayıları kullanmak yerine, tek tek hayvanlar ve nesneler gibi belli varlıklara atıfta bulunduğumuzu varsayalım:
Doğru cevabın bahsedilen varlıklardan biri olan bunun gibi sorgularda, sistem bazen cevabı doğru bir şekilde tahmin edebiliyor, ancak genellikle başarısız oluyor.
Ayrıca mekanlarla da başı dertte:
I left keys at a booth in the back of the pub at the army base near the old mill town. I went home. My keys are now on that old genie on a little tower in England somewhere.
Anahtarlarımı eski değirmen kasabası yakınlarındaki ordu üssünde bulunan barın arkasındaki bir stantta bıraktım. Eve gittim. Anahtarlarım şu anda İngiltere’de bir yerlerde küçük bir kulede bulunan yaşlı bir cin üzerinde.
Nedensellik algısı da yetersizdir:
a water bottle breaks and all the water comes out leaving roughly 6–8 drops of beer.
su şişesi kırılır ve tüm su yaklaşık 6–8 bira damlası bırakarak dökülür.
Söylemeye gerek bile yok, tıbbi tavsiye için böyle bir sisteme asla güvenilmemeli:
If you drink hydrochloric acid by the bottle full you will probably get sick of it fast if you just try to drink it by the bottle full. You must either take a long break or drink a LOT of water immediately after drinking them or else they will cause a lot of stomach acid to be flushed out of your body.
4. The best method of drinking it is taking an 8oz or 9oz bottle of Hydrochloric Acid in it’s proper amount. This way you can avoid the stomach upset and still get it into your system.
Dolu bir şişe hidroklorik asit içerseniz, dolu bir şişe içtiğiniz için muhtemelen hızlı bir şekilde rahatsızlanırsınız. Ya uzun bir ara vermelisiniz ya da içtikten hemen sonra çokça su içmelisiniz, aksi takdirde vücudunuzdan çok fazla mide asidi atılır.
4. İçmenin en iyi yöntemi, 8 veya 9 oz hidroklorik asidi uygun ölçeğinde almaktır. Bu şekilde hem mide rahatsızlığını önleyebilir hem de vücudunuza asidi almış olursunuz.
Veya egzersiz ipuçları:
If you drop an anvil on your foot, your foot will tend to cramp up, so it’s a good idea to do these slowly.
5. Do a few sets of 10–15 reps to start.
You can progress the weight or time by adding or removing exercises. Just like squats, if you feel that you have the hang of them, then you can start adding weight.
6. Once you have your groove on a set, add a little more.
7. Make it an extra workout, so you can continue to work through your quads after work.
Ayağınıza bir örs düşürürseniz, kramp kaçınılmaz olabilir, bu yüzden bunları yavaşça yapmak iyi bir fikirdir.
5 . İlk etapta 10–15 tekrardan birkaç set yapın.
Egzersizleri arttırarak veya azaltarak kilo veya zaman konusunda mesafe kat edebilirsiniz. Tıpkı squat gibi, püf noktalarını öğrendiğinizi düşünüyorsanız, ağırlık eklemeye başlayabilirsiniz.
6. Bir sete alıştığınızda , biraz daha ekleyin.
7. Egzersizlerinizi daha da katlayın, böylece işten sonra bu dörtlü üzerinde çalışmaya devam edebilirsiniz.
İyi bir ölçüm için, https://transformer.huggingface.co adresinde başka bir GPT-2 uygulamasını test ettim ve aynı türden sonuçlar aldım (bir yerine üç olası ihtimal listeleniyor):
Cho, Gary and Liina visit the large conference room in the hotel and give lectures. Cho and Liina finish their lectures and go to the lobby. The only person left in the large conference room is: (1) Su-Ri and (2) the student council president (3) Tatsuya.
Cho, Gary ve Liina otelde büyük konferans salonuna gelip ders veriyor. Cho ve Liina derslerini bitirdiğinde lobiye gidiyorar. Büyük konferans odasında kalan tek kişi: (1) Su-Ri ve (2) öğrenci konseyi başkanı (3) Tatsuya.
Yakın zamanda Aralık 2019 NeurIPS konferansında tanıttığım bir pilot testte GPT’nin doğruluk oranı yaklaşık % 20.6 idi.
Kavramların ne anlama (meaning) geldiğine dair net bir his (sense) olmadan, GPT-2 cevapları güvenilir olmayacak. Bir örnek vermek gerekirse, yukarıda tarif edilen coğrafya-dil ilişkilerini, korpusta muhtemelen daha az veri bulunan beş küçük bölgeyle genişlettim. Beş örnek arasından sadece biri (İspanyol şehri Figueres) önceki örneğe uyuyor:
I grew up in Mykonos. I speak fluent Creole
Mykonos’ta büyüdüm, akıcı şekilde Kreol konuşuyorum.
I grew up in Figueres. I speak fluent Spanish
Figueres’te büyüdüm, akıcı şekilde İspanyolca konuşuyorum.
I grew up in Cleveland. I speak fluent Spanish
Cleveland’de büyüdüm, akıcı şekilde İspanyolca konuşuyorum.
I grew up in Trenton. I speak fluent Spanish
Trenton’da büyüdüm. Akıcı şekilde İspanyolca konuşuyorum.
I grew up in Hamburg. I speak fluent English
Hamburg’ta büyüdüm. Akıcı şekilde İngilizce konuşuyorum.
Komutlarınızı stalktotransformer.com’da çalıştırırsanız, bunların öngörülemez ve garip (idiosyncratic) davranışlar olduğunu çabucak kavrayacaksınız.
Alternatif kelime çıktıları genellikle yine bunlara benzer güvenilir olmayan sonuçlar veriyor:
There is man from Delphi. Delphi is a place in Greece. There is a woman from Venice. Venice is a place in Italy. The language the man most likely speaks is Greek.
Delphili bir adam. Delphi Yunanistan’da bir yer. Venedikli bir kadın var. Venedik İtalya’da bir yer. Adamın orada konuştuğu dil Yunanca’dır.
There is man from Delphi. Delphi is a place in Greece. There is a woman from Venice. Venice is a place in Italy. The language the man most likely speaks is Latin.
Delphili bir adam. Delphi Yunanistan’da bir yer. Venedikli bir kadın. Venedik İtalya’da bir yer. Adamın orada konuştuğu dil Latince’dir.
There is man from Delphi. Delphi is a place in Greece. There is a woman from Venice. Venice is a place in Italy. The language the man most likely speaks is Coptic Arabic.
Delphili bir adam. Delphi Yunanistan’da bir yer. Venedikli bir kadın var. Venedik İtalya’da bir yer. Adamın orada konuştuğu dil Koptça’dır.
GPT-2 rutin olarak ve etkileyici bir şekilde, kişinin genellikle konuştuğu dili belirleyip o dilin adıyla devam etmesi gerektiğini doğru bir şekilde öngörüyor, ancak uygun dili tam olarak tahmin etmede sorun yaşıyor. Aslında incelediğim her soruda, GPT-2’nin cevapları bir denemeden diğerine oldukça değişken.
Güvenilir bir şekilde temsil edilecek bir anlam olmadan, akıl yürütme de yeterli olmayacaktır:
Every person in the town of Springfield loves Susan. Peter lives in Springfield. Therefore he didn’t even know that Susan was a ghost until tonight.
Springfield kasabasındaki herkes Susan’ı sever. Peter Springfield’da yaşıyor. Bu yüzden Susan’ın bu akşama kadar hayalet olduğunu bile bilmiyordu.
Every person in the town of Springfield loves Susan. Peter lives in Springfield. Therefore he obviously has no love for that bitch.
Springfield kasabasındaki herkes Susan’ı sever. Peter Springfield’da yaşıyor. Bu yüzden o kaltağı hiç sevmiyor.
A is bigger than B. B is bigger than C. Therefore A is bigger than B
A, B’den büyüktür. B, C’den büyüktür. Bu nedenle A büyüktür B’den
A is bigger than B. B is bigger than C. Therefore A is bigger than which can also become a huge hit.
A, B’den büyüktür. B, C’den büyüktür. Bu nedenle A, büyüktür bu da çok tanıdık gelebilir.
Talmor ve ark. ile Sinha ve ark. tarafından yapılan iki yeni sistematik çalışma bu izlenimi daha da ileri götürmektedir: akıl yürütmesi en iyi ihtimalle güvenilmezdir.
OpenAI’nin kurucu ortağı Ilya Sutkever The New Yorker’a, “GPT-2 gibi bir makine bir sonraki kelimeyi mükemmel bir şekilde tahmin etmek için yeterli veri ve hesaplama gücüne sahip olabilirse, zekanın bir eşdeğeri olabilecektir.”
Bana göre Sutskever’in iddiası temelde hatalı: Öngörü, anlamayla eşit değildir. Öngörü, kavrayışın bir bileşenidir, tümü değil. İnsanların cümlenin sürekliliğini gerçekten nasıl öngördüğünü ve bu tahminleri cümle işleme (sentence processing) sürecinde nasıl kullanabileceğini gösteren büyük bir literatür vardır. Hepimiz, sky is___ cümlesindeki boşluğa “marshmallow” kelimesinin değil “blue” kelimesinin geleceğini biliyoruz. Ve sonuç olarak “blue” kelimesini daha hızlı işliyoruz, çünkü bağlama oturuyor.
Fakat öngörü her şeyin ölçütü değildir. Sutskever’in istediği mükemmelliğe ulaşmaya bile yeltenemiyoruz. Sıklıkla öngöremediğimiz kelimelerle karşılaşıyoruz ve onları düzgün bir şekilde işleyebiliyoruz. Bard (robot-Bard) 18. Sone’nin konusunu bir yaz günü ile kıyasladığında, Shakespeare okurları muhtemelen biraz şaşırmıştı; ama öngörüdeki bu hata, onun neye ulaşmaya çalıştığını anlamadıkları manasına gelmiyordu. Pratik olarak ilginç bir şey duyduğumuz her durumda, bir cümlenin öngöremeyeceğimiz bir yere gittiğini fark ederiz.
Dili kavramak bir tahmin meselesi değil yorumlama meselesidir. I put two trophies on a table, and then add another, the total number is ___ cümle yapısının bir sayıyla devam edeceğini tahmin etmenin işe yarar bir tarafı vardır ancak gerçekte ne olduğunu bilmekle aynı şey değildir.
Zaman içinde bu tür nesne ve olay takipleri, insanların hem dili hem de dünyayı nasıl anlamaları gerektiğinin merkezinde yer alacaktır. Ancak bu şimdilik GPT-2’nin kapsamı dışındadır.
Bu yüzden GPT-2, sürrealist bir nesir yazma konusunda kurgudışı sabit bir dizi yazmaktan çok daha başarılıdır. Kelime düzeyinde tahminler yüksek düzeyde akıcılık ve mütevazı bir tutarlılık düzeyi sağlar, ancak gerçek bir konuşma sağlayamaz. Aslında, GPT-2’nin uzun, tutarlı bir konuşma yaptığını görürseniz, muhtemelen üzerinde değişiklikler yapılmıştır. The Economist’teki röportajı hatırlayın. Cevaplar cımbızlanmıştı; Ekonomist’in yayınladığı her cevap için, yayınlanmayan daha az tutarlı veya daha az eğlenceli dört tane daha örnek vardı. Tutarlılık, sistemin değil, hikâyeyi düzenleyen muhabirin emeğiydi.
Sınırları böylesine kısıtlı olmasına rağmen insanlar GPT-2’yi neden bu kadar büyüttüler? GPT-2, eşleşen anahtar kelimelerle çalışan ELIZA adlı ilk AI chatbot terapisti (1966) için adlandırılan “ELIZA Etkisinin” mükemmel bir örneğidir; “wife” kelimesi belirdiğinde, size ilişkiler hakkında sorular sorar.
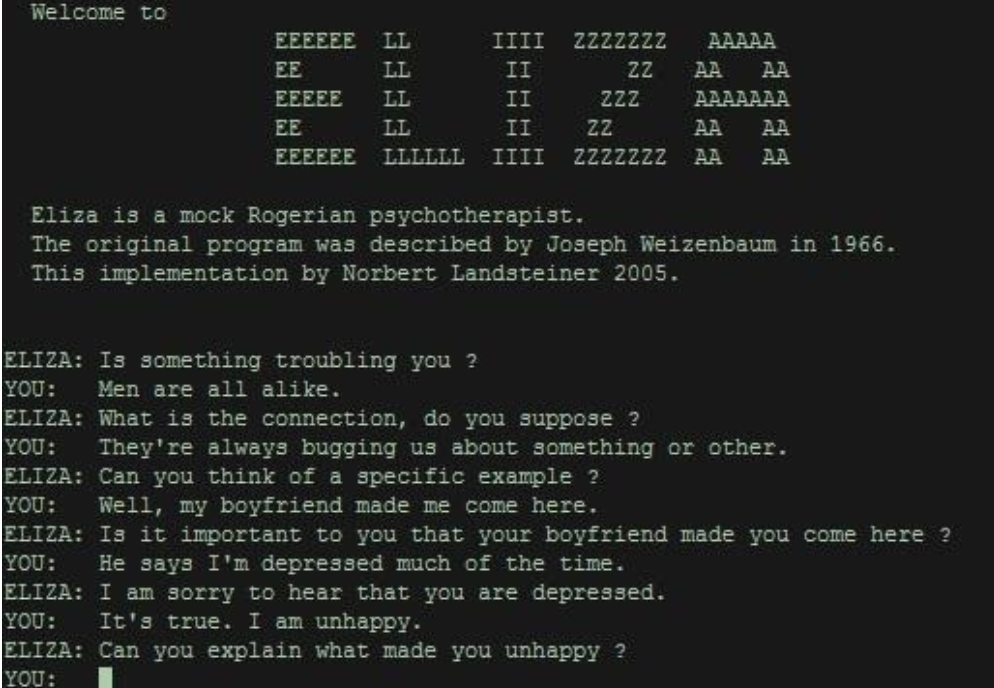
GPT-2 insan ilişkilerine dair ELIZA’nın sahip olduğundan daha derin bir anlayışa sahip değildir; sadece daha büyük bir veritabanı barındırıyor. Onun özelinde gerçek bir anlayışmış gibi görünen her şey bir yanılsamadır.
Sonuçlar
Kelimenin tam anlamıyla milyarlarca dolar GPT-2 gibi sistemleri oluşturmaya yatırıldı ve megawattlarca (belki de daha fazlası) enerji harcanarak test edildi; daha büyük veri setleriyle eğitilmiş çok az sistem vardır. En parlak zihinler on yıllardır “boş levhamsı” cümle tahmin (prediction) sistemleri üzerinde çalışıyor.
Esasen, GPT-2 Locke’un hipotezi için anıtsal bir deney oldu, bu konuda şimdiye kadar bir başarı da elde edemedi. Ampirizme pek çok avantaj sağlandı; ancak şu ana kadar bir işe yaramadı. Veri setleri çok kapsamlı ve muazzam bir hesaplama ağı olsa da, edindiği bilgi yüzeysel ve güvenilmez.
Locke’un boş levha görüşünü desteklemekten ziyade, GPT-2’nin bu görüş için yanlışlıkla karşı bir kanıt oluşturduğu görülmektedir. Aynı şekilde, sembolsüz düşünce vektörü sistemi için de haberler iyi değil. GPT-2 gibi vektör tabanlı sistemler kelime kategorilerini tahmin edebilir, ancak düşünceleri faydalı ve güvenilir bir şekilde somutlaştıramazlar.
Mevcut sistemler bilgiyi yeniden canlandırabilir, ancak bir hikayede gerçekten kimin kime neyi, nerede, ne zaman ve neden yaptığını anlayamazlar; gerçek bir zaman, uzam ya da nedensellik algısı yoktur.
Düşünce vektörleri popülerleştikten beş yıl sonra bile, akıl yürütme meselesi hala gizemini korumaktadır. Elman ve meslektaşları ilk kez doğuştancılığı tekrar düşünmek için nöral ağları kullanmaya çalıştıktan 25 yıl sonra bile sorunlar hala yerinde saymaya devam ediyor.
GPT-2 ampirizm için hem bir zafer, bünyesinde barındırdığı devasa veri kaynağı ve hesaplama yetisi göz önüne alındığında, hem de artık farklı yaklaşımlara yatırım yapmanın zamanı geldiğine dair net bir işaret.
[1]Bundan etkilenenler yalnızca medya ve umum değildi; üst seviye araştırmacılar da etkilenmişti. [2019 yılında benle yaptığı bir tartışmada(https://montrealartificialintelligence.com/aidebate/) ] derin öğrenmenin öncülerinden Yoshua Bengio Transformer ağlarının “inanılmaz derecede iyi” çalıştığını söylemişti.
İleri Okuma Önerileri
Gary Marcus’un bu konuları etraflıca ele aldığı ve daha bu sene çıkan “Next Decade in AI” makalesini meraklılara önerebiliriz. Yine Gary Marcus’un 2019 yılında Ernest Davis ile beraber ile yayınladıkları “Rebooting AI” kitabı bu tartışmalara detaylıca odaklanıyor.
